
Международная лаборатория языковой конвергенции запустила новый сайт с ресурсами
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Одной из задач Международной лаборатории языковой конвергенции является создание новых открытых электронных ресурсов, посвященных малым языкам России, диалектам русского языка и контактным вариантам русской речи. За четыре с лишним года этих ресурсов стало так много, что лаборатории пришлось обзаводиться собственным сервером и создавать специальный сайт, на котором удобно размещены все ресурсы. Особенно плодотворным оказался коронавирусный 2020-й. Поскольку отменились все поездки, многие полевые лингвисты сочли правильным направить свои усилия на обработку уже собранных данных: расшифровку и разбор записанных текстов, доработку баз данных. Сотрудники лаборатории воспользовались этой паузой для того, чтобы совместно с исследователями из разных университетов и институтов Москвы и Санкт-Петербурга сделать удобные и открытые ресурсы для лингвистов.
Значительная часть ресурсов, созданных при участии лаборатории, – это устные корпуса, то есть собрания текстов, записанных в селах и небольших городах России, расшифрованных в программах Praat или Elan и снабженных поисковой системой. Важной особенностью таких корпусов является выравнивание текста и звука; это позволяет искать в текстах нужные слова и грамматические явления и не только просматривать, но и прослушивать искомые фрагменты. Создание устных корпусов – очень трудоемкая задача. Чтобы сделать корпус диалектной речи объемом шесть-семь часов, нужно поехать в труднодоступное место, говорить с местными людьми, записывать их речь на диктофон, получив на это их согласие. Следующий этап – это расшифровка. Лингвистам нужна качественная, весьма точная расшифровка, которую мало кто умеет делать, учитывая, что речь имеет много отличий от привычной нам речи крупного города. Как ни странно это может показаться, но, по опыту лаборатории, именно этот этап самый трудозатратный и требует самой высокой квалификации. По сути дела, хорошо расшифровывают только специалисты: те, кто знает особенности говора, специфику местной жизни, локальную географию и историю региона (ведь люди часто рассказывают о событиях прошлого). Поэтому лаборатория сотрудничает с теми лингвистами, которые работают в разных регионах России, предлагая им поддержку в обработке данных. На последнем этапе сотрудники лаборатории собирают тексты в корпус, и здесь важно, чтобы конечный продукт имел удобный интерфейс и предоставлял возможность разного рода сортировки и поиска. Таким образом в 2020-21 годах были созданы корпуса говора деревни Хиславичи (совместно с сотрудником СПБГУ А.И. Рыковой), деревень Нехочи и Лужниково (ИРЯ РАН, А.В. Тер-Аванесова и А.В. Малышева), цыганского варианта русской речи (Институт славяноведения, К.А. Кожанов), бесермянского русского (Т.А. Архангельский, Университет Гамбурга) и другие. Сейчас лаборатория предоставляет доступ к семнадцати корпусам русского языка, в том числе к десяти корпусам диалектной речи и семи корпусам русской речи таких людей, для кого русский является вторым языком, включая корпус якутско-русского переключения кодов. Это, безусловно, самая большая коллекция устных корпусов не только русского, но и, шире, какого бы то ни было славянского языка. Кроме того, при участии лаборатории были созданы устные корпуса других языков России: башкирского (команда из СпбГУ и ИЛИ РАН), хакасского (ИЯ РАН), абазинского, адыгейского и кабардинского.
Помимо устных корпусов, на новом сайте размещены ссылки на различные ресурсы, связанные с языками Дагестана – главным объектом полевых исследований лаборатории.
Во-первых, это Атлас многоязычия Дагестана – ресурс, который дает доступ к информации о многоязычии более чем 50 сел Дагестана, полученных в ежегодных полевых поездках, и расположенная там же база переписей Дагестана.
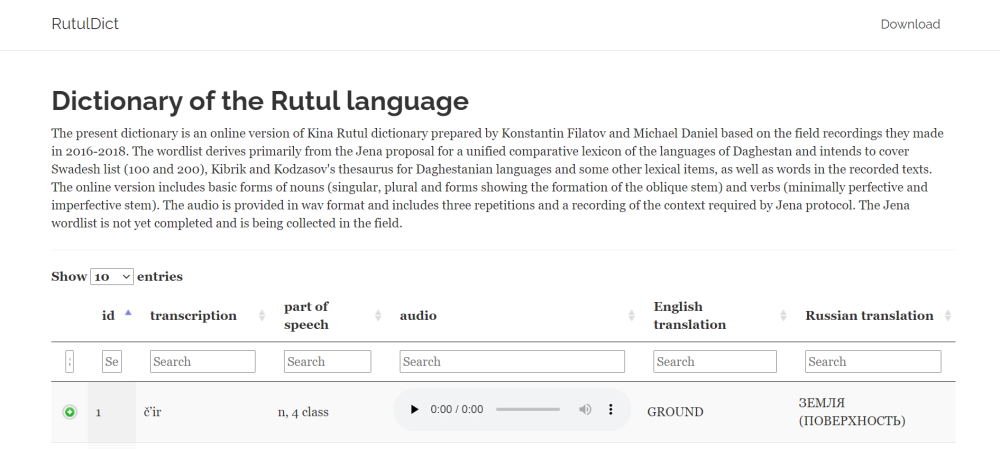
Во-вторых, это несколько словарей малых дагестанских языков, составленных при участии сотрудников лаборатории (мегебский, тукитинский и рутульский). Эти словари собираются исследователями этих языков, которые сами являются их носителями, по определенной схеме, разработанной специально для лексикографической документации языков Кавказа нашими коллегами из университета Йены. Кроме уже вывешенных словарей в разной степени готовности находятся словари еще нескольких языков – ахвахского (северный диалект) и каратинского.
В-третьих, это база стословных списков дагестанских диалектов, собранных в настоящий момент в 21 селе. Стословные списки Сводеша – традиционный способ оценки дистанции между разными языками. Однако в Дагестане уровень расхождения между вариантами языка, на которых говорят жители соседних сел, часто граничит с тем, что в других регионах принято считать разными языками; и единой, общепринятой номенклатуры языков нет. Поэтому в рамках данного проекта мы отказались от любых предвзятых оценок и стараемся собрать стословные списки в каждом селе – по крайней мере, в определенных, наиболее интересных в этом отношении районах Дагестана – чтобы оценить уровень расхождения не между абстрактными “языками”, а между конкретными говорами, и на основании этих данных объективно оценить межъязыковые и междиалектные различия.
В-четвертых, база данных заимствований, собранных в ряде сел Дагестана по определенной методике, разработанной в лаборатории. Главная особенность всех этих ресурсов по языкам Дагестана – их ориентация на уровень конкретного села, а не целой языковой или диалектной зоны. Это позволяет исследовать контактные явления на гораздо более точном и детальном уровне, чем это делалось до сих пор.
И, наконец, здесь же располагается Типологический атлас Дагестана, где собираются данные по фонетическим и грамматическим особенностям языков Дагестана и языков некоторых соседних с ним народов. В создании Атласа активное участие принимают студенты и магистранты Школы лингвистики. Этот ресурс был открыт в 2021 году и продолжает активно развиваться, чтобы стать основой для ареальных исследований языков восточного Кавказа.
За всеми ресурсами стоит большая концептуальная и техническая работа по разработке технического дизайна и интерфейса. Не все ресурсы еще вывешены – впереди корпуса марийского и рутульского языков, оцифрованный словарь хваршинского языка (автор М.Ш. Халилов), несколько новых диалектных корпусов и пополнение уже имеющихся ресурсов.
![]()