
The International Linguistic Convergence Laboratory has launched a new website with resources
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
One of the tasks of the International Linguistic Convergence Laboratory is the creation of new open electronic resources dedicated to the minor languages of Russia, Russian dialects and contact varieties of Russian speech. For more than four years, these resources have become so abundant that the laboratory had to acquire its own server and create a special website where all the resources are conveniently located. The pandemic year 2020 proved especially fruitful. Since all trips were canceled, many field linguists focused their efforts on processing the data that had already been collected: transcription and parsing of the recorded texts, and finalizing the databases. The laboratory members took advantage of this pause to create convenient and open resources for linguists in collaboration with researchers from various universities and institutes of Moscow and St. Petersburg.
A significant part of the resources created with the participation of the laboratory are spoken corpora, – collections of texts recorded in villages and small towns of Russia, transcribed in Praat or Elan and equipped with a search engine. An important feature of such corpora is the alignment of text and sound, which allows you to search for the necessary words and grammatical phenomena in the texts and not only view but also listen to the desired fragments. The creation of spoken corpora is a very time-consuming task. In order to create a corpus of dialect speech with a duration of six to seven hours, you need to go to a hard-to-reach place, talk with local people, and record their speech on a dictaphone after having obtained their consent. The next step is transcription. Linguists need very accurate high-quality transcripts, which few people know how to do, given that such dialectal speech has many differences from the speech of large cities that we are used to. Strange as it may seem, according to the laboratory's experience, this stage is the most labor-intensive and requires the highest qualification. In fact, only specialists can transcribe well: those who know the peculiarities of the dialect, the specifics of local life, local geography and the history of the region (after all, people often talk about events of the past). Therefore, the laboratory cooperates with those linguists who work in different regions of Russia, offering them support in data processing. At the last stage, laboratory members collect texts into a corpus. Here it is important that the final product has a user-friendly interface and provides the ability to sort and search in various ways. Thus, in 2020-21, corpora were created for the village of Khislavichi (together with A.I. Rykova, St. Petersburg State University), the villages of Nekhochi and Luzhnikovo (IRL RAS, A.V. Ter-Avanesova and A.V. Malysheva), Romani Russian (Institute of Slavic Studies, K.A. Kozhanov), Besermyan Russian (T.A. Arkhangelsky, University of Hamburg) and others. Now the laboratory provides access to seventeen corpora of the Russian language, including ten corpora of dialectal speech and seven corpora of Russian speech for people who speak Russian as a second language, including the corpus of Yakut-Russian code switching. This is undoubtedly the largest collection of spoken corpora not only for Russian, but also, more broadly, for any Slavic language. In addition, with the participation of the laboratory, the spoken corpora of other languages of Russia were created: Bashkir (a team from St. Petersburg State University and ILS RAS), Khakas (IL RAS), Abaza, Adyghe and Kabardian.
In addition to the spoken corpora, the new website contains links to various resources related to the languages of Daghestan, which form the main object of the laboratory's field research.
Firstly, this includes the Atlas of Multilingualism in Dagestan, a resource that provides information on the multilingualism of more than 50 villages in Daghestan, obtained in annual field trips. It also contains a Daghestanian census database.
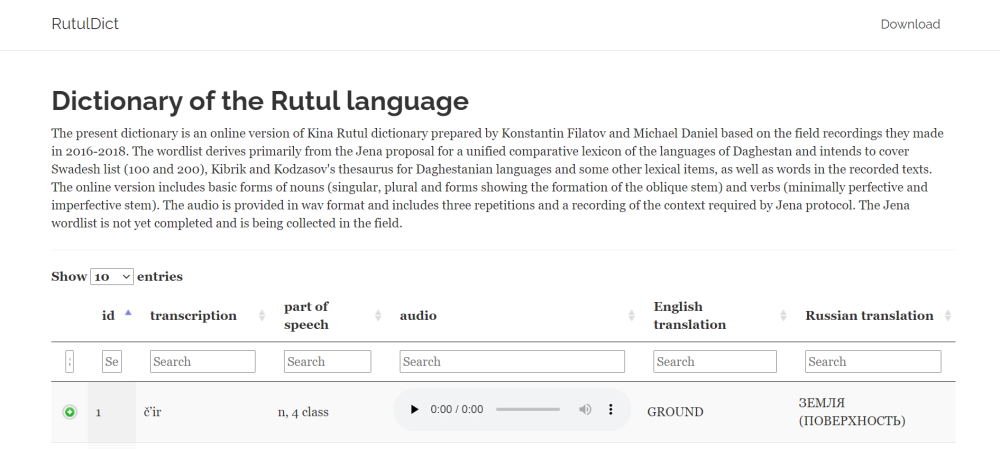
Secondly, there are several dictionaries of minor Daghestanian languages, compiled with the participation of laboratory members (Mehweb, Tukita and Rutul). These dictionaries are collected by researchers of these languages, who are themselvesnative speakers. Data are collected following a method developed specifically for the lexicographic documentation of the languages of the Caucasus by our colleagues from the University of Jena. In addition to the dictionaries that are already available, dictionaries of several other languages are in varying degrees of readiness – Akhvakh (Northern dialect) and Karata.
Thirdly, this is a database of hundred-word lists in Daghestanian dialects, which so far have been collected in 21 villages. Swadesh hundred-word lists are a traditional way of assessing the distance between different languages. However, in Dagestan, the level of discrepancy between the variants of the language spoken by residents of neighboring villages often borders on what is considered to be different languages in other regions; and there is no single, generally accepted nomenclature of languages. Therefore, within the framework of this project, we abandoned any preconceived assessments and are trying to collect hundred-word lists in each village – at least in certain regions of Daghestan that are most interesting in this respect – in order to assess the level of discrepancy not between abstract “languages”, but between specific dialects, and on the basis of these data to objectively assess the interlanguage and interdialect differences.
Fourthly, a database of borrowings collected in a number of villages in Daghestan according to a certain methodology developed in the laboratory. The main feature of all these resources on the languages of Daghestan is their focus on the level of a particular village, and not on the whole linguistic or dialectal zone. This makes it possible to study contact phenomena at a much more precise and detailed level than has been done so far.
And, finally, there is the Typological Atlas of the languages of Daghestan, which contains data on linguistic features of the languages of Daghestan and several neighboring languages. Students and undergraduates of the School of Linguistics are actively involved in the creation of the Atlas. This resource was started in 2021 and continues to actively develop, in order to become a basis for areal studies of the languages of the eastern Caucasus.
A lot of conceptual and technical work goes into the development of technical designs and interfaces. Not all resources have been posted yet – the corpora of the Mari and Rutul languages are to be released, as well as the digitized dictionary of the Khwarshi language (by M.Sh. Khalilov), several new dialect corpora and the expansion of the existing resources.