
Четыре года lingtypology – программному пакету для картографирования и лингвистической типологии

Лингвисты давно начали отмечать на карте разные языковые явления. Первые лингвистические карты были созданы диалектологами еще в конце XIX века, и проекты атласов диалектов крупных языков развивались в течение всего XX века. С расцветом лингвистической типологии в 1980-х годах появилась потребность в создании карт, на которых бы отображались те или иные явления в большом наборе неродственных языков. Наиболее масштабным проектом такого типа стал The World Atlas of Language Structures, изданный сначала в виде книги, а потом ставший доступным в виде онлайн базы данных.
Еще четыре года назад у лингвистов не было простого инструмента с элементарной функцией раскраски набора точек на карте в разные цвета. Нельзя сказать, что инструментов не было вообще, но они были тяжеловесными и требовали больших усилий от исследователя. Эта задача привела Георгия Мороза, сотрудника лаборатории языковой конвергенции и Школы лингвистики, к созданию нового программного продукта, который оказался очень востребованным – lingtypology. Этот свободно распространяемый пакет на языке R для картографирования и лингвистической типологии, с момента публикации пакета на CRAN 29 декабря 2016 скачали более 25 тысяч раз (впервые пакет был опубликован 12 июня 2016 на github, скачивания с github в подсчете не учитываются).
Рассказывает Георгий Мороз
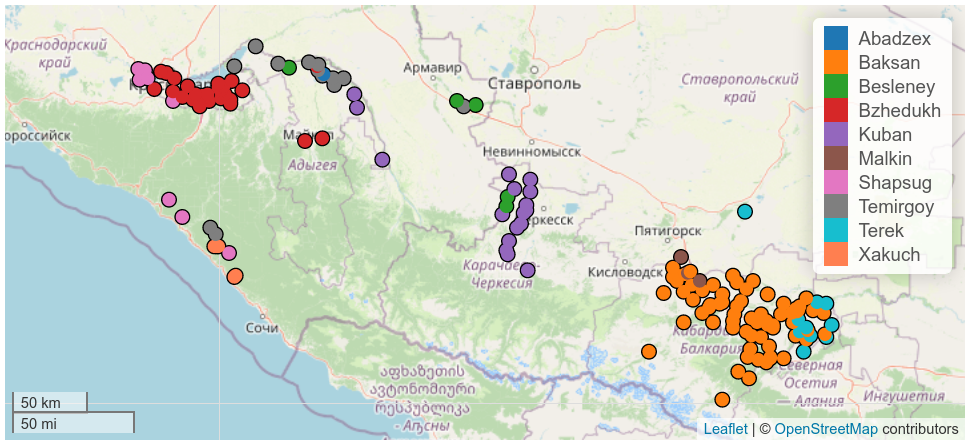
Когда этот инструмент появился, создание карт стало делом одной строчки. Открылись новые горизонты: как любую визуализацию, карты в лингвистике часто использовали как способ проиллюстрировать какую-то мысль. Теперь же карта стала инструментом исследования, позволяющим посмотреть на связи различных лингвистических переменных. Например, на карте ниже представлено распространение адыгских диалектов в России, и, если исследователь захочет провести новое исследование на основе выборки диалектов, он(а) сможет выбрать из каждого диалекта максимально удаленные друг от друга населенные пункты.
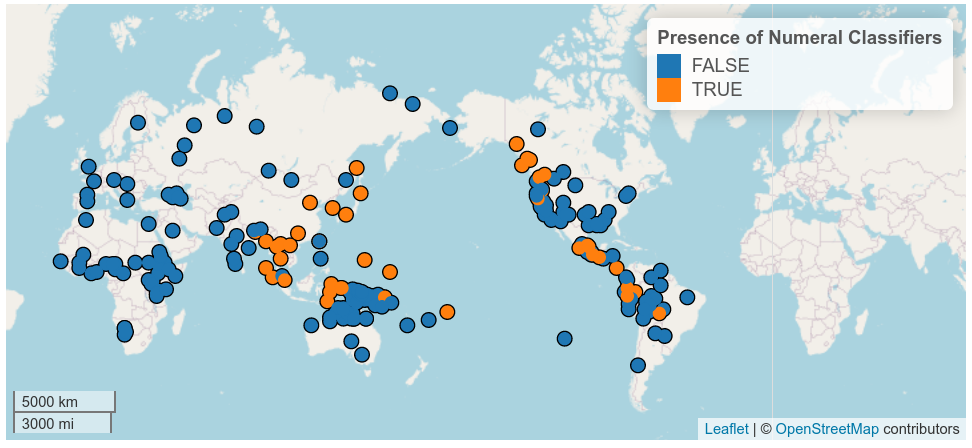
Вторая функция пакета, о которой, к сожалению, многие лингвисты все еще не знают, это доступ к лингвистическим базам данных. Сейчас поддерживаются восемь баз данных, созданных международными коллективами лингвистов. Самые известные – это Glottolog, WALS, AUTOTYP, PHOIBLE и Affix Borrowing database. Важно даже не то, что теперь можно при помощи всего одной команды скачать данные из этих источников, а то, что теперь исследователи могут соединить это со своими данными и визуализировать, как связаны разные наборы данных между собой. Я планирую расширять список доступных баз данных.
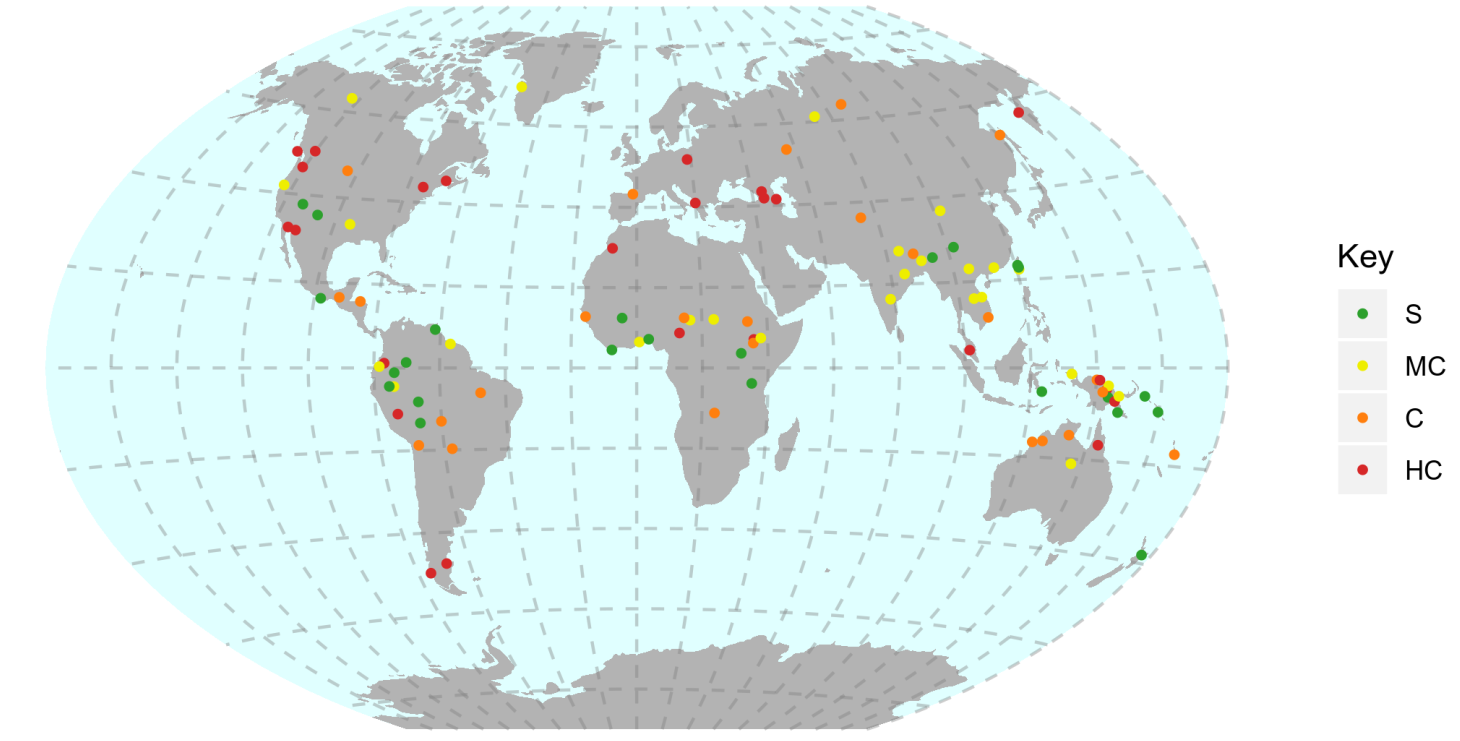
Важным свойством получаемых карт является то, что они основаны на JavaScript библиотеке Leaflet, которая делает интерактивные карты (т. е. пользователь сам может увеличить или уменьшить масштаб по своему выбору). В результате можно создавать динамические сайты (см., например, The World Consonant Alternation Database) и не бояться визуализировать сразу много данных: ведь при желании пользователь может приблизиться и рассмотреть детали, которых не видно на первый взгляд. Однако это оказалось и слабым местом lingtypology. Дело в том, что многие журналы требуют рисунки в высоком разрешении, а интерактивные карты, которые получаются в lingtypology, часто не удовлетворяет этим требованиям. В связи с этим я планирую разработать статический шаблон, как например, было сделано для книги Шелис Истердэй “Highly complex syllable structure: A typological and diachronic study”:
Несколько факторов помогло мне в разработке пакета. Во-первых, это люди, которые создали и поддерживают базу данных Glottolog: благодаря им пользователям пакета чаще всего не нужно вручную вводить координаты языков, которые они хотят визуализировать. Во-вторых, это общество ROpenSci, благодаря которому пакет получил ревью, позволившее значительно улучшить пакет. В-третьих, конечно, это мои коллеги, друзья и студенты, которые, решив использовать пакет (причем не только в лингвистике!), обнаружили и сообщили мне об ошибках, а также ставили передо мной все новые и новые задачи. Один студент Школы лингвистики, Михаил Воронов, даже написал аналог пакета на языке программирования Python. В-четвертых, это концепция Open Source, благодаря которой я получил фидбек и помощь от самых разных лингвистов по всему миру после того, как написал о пакете в лингвистическую рассылку LINGUIST List.
Мороз Георгий Алексеевич
Международная лаборатория языковой конвергенции: Младший научный сотрудник