
TALD (Typological Atlas of the Languages of Daghestan) v. 1.0.0 Now Public
The Linguistic Convergence Laboratory has released TALD: the Typological Atlas of the Languages of Daghestan. This new resource provides information about linguistic structures that are characteristic of Daghestan, and offers different types of map visualizations to illustrate the geographical and genealogical distribution of features.
 v. 1.0.0 Now Public")
We are happy to announce the first release of TALD (Typological Atlas of the Languages of Daghestan) v. 1.0.0, available here: http://lingconlab.ru/dagatlas/.
TALD is a tool for the visualization of linguistic structures that are characteristic of Daghestan, i.e., a resource similar to the World Atlas of Language Structures (WALS) Online (https://wals.info), but specialized in a particular area and aiming at maximum coverage of local languages and dialects. Originally, the focus of the project were the languages of the East Caucasian family spoken in Daghestan, but the scope of the Atlas has since been broadened to include adjacent areas where East Caucasian languages are spoken, as well as non-related languages spoken in Daghestan.
In its current version the Atlas consists of 28 datasets with information on linguistic features mostly in the areas of phonology, morphology and - to a lesser extent - the lexicon. However, the Atlas is intended as a dynamic resource whose contents are constantly updated, and we plan to gradually add new topics to cover the areas that have not been dealt with so far.
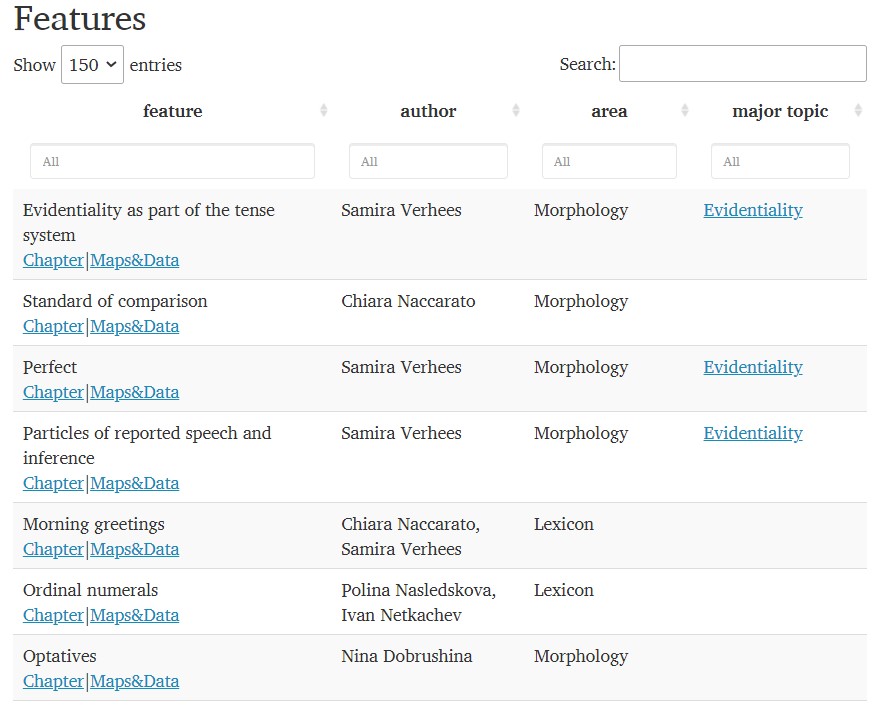
Information was retrieved from published grammars and other relevant literature, and organized in datasets. Each dataset is accompanied by an introductory chapter and several map visualizations.
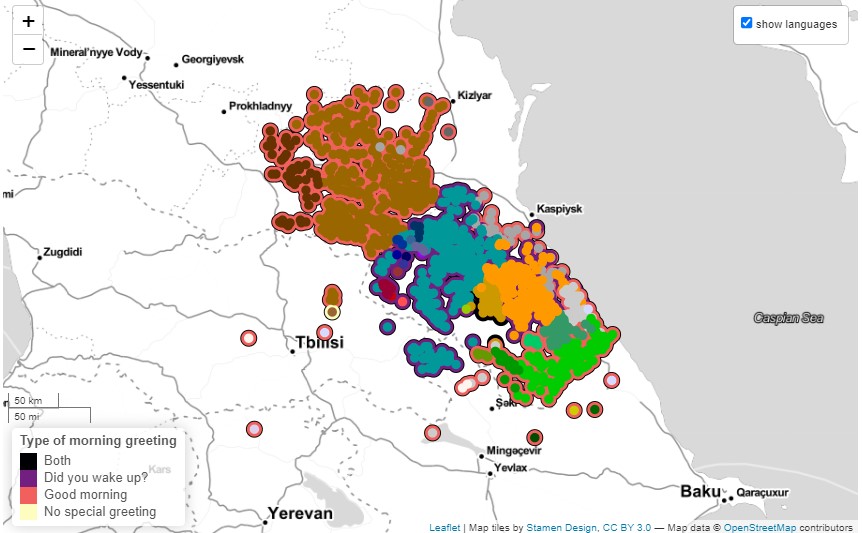
A unique feature of the Atlas is its approach to feature visualization. Along with maps in which each language corresponds to a single dot, we offer another type of visualization based on data extrapolation. Within this type of visualization each language corresponds to several dots indicating the villages in which the language is spoken. For this purpose we use a database including coordinates and information about the language spoken in each village. This approach to visualization allows the user to compare general maps with one datapoint for each language and more fine-grained visualizations that show the boundaries between languages more clearly.
For map visualization we use the Lingtypology package (Moroz 2017) for R, whereas examples and glosses in chapters are rendered with the Lingglosses package (Moroz 2021). Both packages were specifically designed for the Atlas by George Moroz, and are now widely used within other projects too.
The utility of this resource is threefold: it offers accessible and retrievable information about linguistic features in the languages of Daghestan; it provides a searchable database of literature references on specific languages, idioms, and topics; map visualizations with color-coding for language groups illustrate the geographical and genealogical distribution of features.
Any comments, remarks or suggestions on how to improve the current form of the Atlas and its contents can be sent via email to cauatlas@gmail.com or submitted as issues on our GitHub page https://github.com/LingConLab/TALD.
If you carry out research on the languages of Daghestan and would like to contribute a chapter or data to the Atlas, please contact us at cauatlas@gmail.com.